Most of the conversations we have with clients in the first year of a project are about features. Most of the conversations in years two and three are about uptime, security patches, and "why did the form break yesterday." This post is about that second conversation — the post-launch operations retainer we run for clients whose websites, MIS systems, and Flutter apps we either built or took over. It is the least glamorous part of what we do. It is also the part that determines whether the client gets to spend year three building new things or fighting fires.
What the monthly retainer covers
Four layers, priced as one fixed monthly fee:
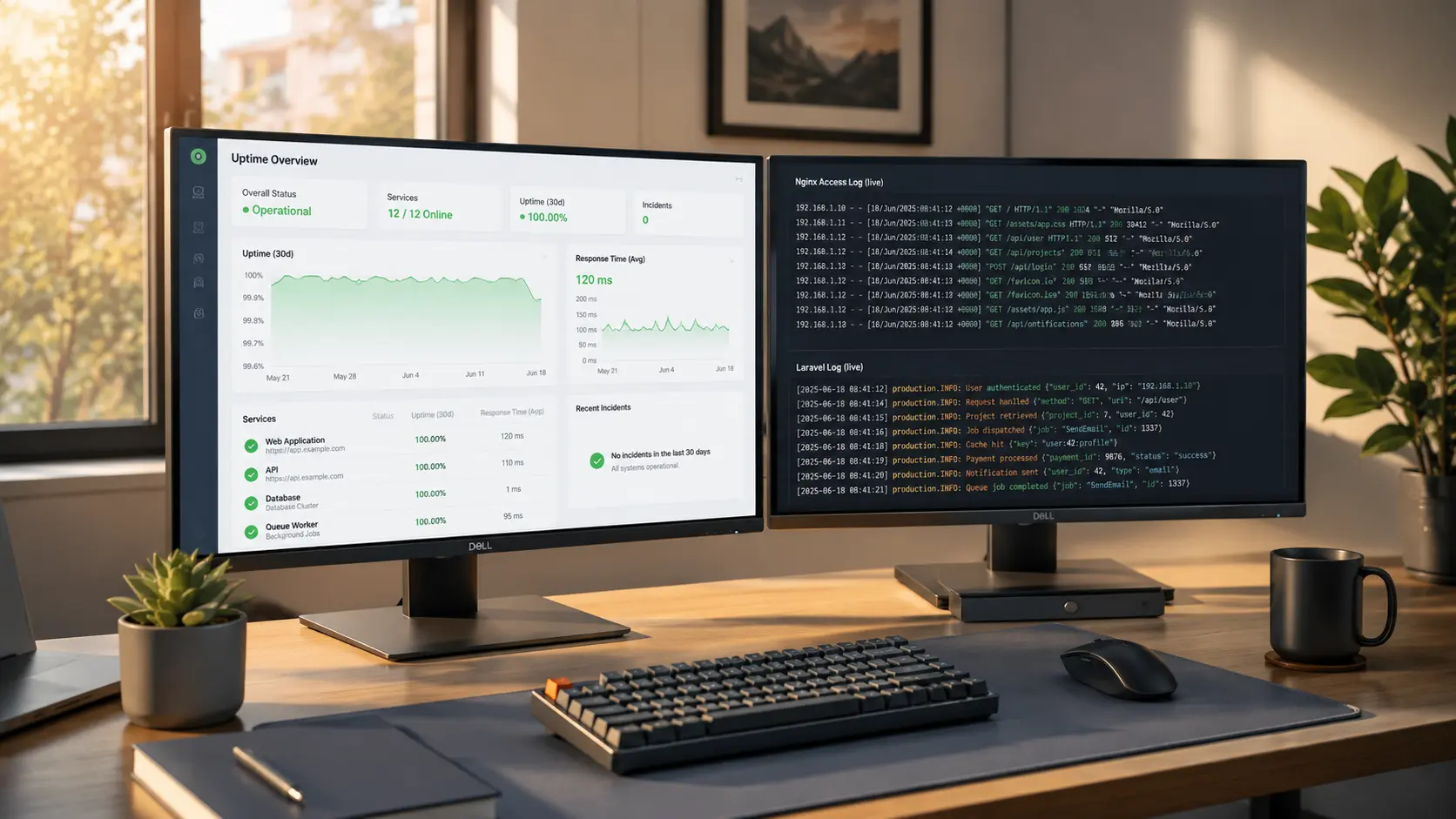
Monitoring. Uptime checks every 60 seconds from three geographies, alerting on three failures in a row. Synthetic transactions for the three flows the client cares about most (login, checkout, contact form). Server-level metrics — CPU, RAM, disk, swap, queue depth — with thresholds calibrated to the actual production baseline, not vendor defaults. Centralized logs (Nginx, Laravel, MySQL slow query) shipped to one place so we can actually answer "what happened at 3:14am last Tuesday."
Security patching. Weekly review of CVEs for the client's stack — PHP, Laravel, Nginx, MySQL, the top 20 Composer packages, the OS. Critical CVEs patched within 24 hours, high within a week, medium within the monthly cycle. Quarterly SBOM regeneration. Annual penetration scan against the public surface. Every patch is logged and the client gets a one-line changelog every Monday.
Backups and disaster recovery. Database backups every hour, file backups daily, both offsite. Restore tested quarterly — actually tested, not "we have backups, it's fine." Documented RTO (recovery time objective) and RPO (recovery point objective) numbers the client signs off on. A written runbook for "site is down, DNS is gone, and the senior engineer is on a plane."
Small-change capacity. A fixed monthly bucket of hours (typically 10–30 depending on system complexity) for non-architectural changes: a new field on a form, a copy edit, a report tweak, a small admin-panel addition. Unused hours roll forward two months and then expire. The bucket exists so clients don't have to write a change order for a 20-minute job.
What it does NOT cover
Three things, called out in the contract so there are no surprises:
New modules and major features. Anything that materially changes the data model, adds a new third-party integration, or requires UX design is a separate scoped project. We bid it fixed-price after a discovery sub-engagement.
Hosting infrastructure costs. The client owns and pays the cloud provider directly. We do not mark up AWS, GCP, DigitalOcean, or local Taiwan hosting bills. This keeps incentives clean: we have no reason to over-provision.
Emergencies caused by client-side changes we did not make. If the marketing team installs a new tracking script that breaks checkout, we fix it — but the fix bills out of the small-change bucket. If the bucket is empty, it bills hourly. We never invoice the fix to "monthly retainer" silently.
Why "we'll handle hosting ourselves" is so expensive
About a third of new clients tell us in year one that they want to handle their own ops. The math, every single time, ends the same way: by month 14, somebody has missed a critical CVE (NGINX Rift, the laravel-lang supply chain attack, the Gitea container-image leak — all in May 2026 alone), the SSL certificate has lapsed once, the backups were never tested, and the database has run out of disk twice. The remediation project — security incident response, infrastructure hardening, backup restoration testing, the works — typically costs 6–10 months of what the retainer would have cost.
This is not a sales pitch; it is observation. The clients who do best operationally are split roughly evenly between two groups: those with their own competent DevOps function (we hand off cleanly, no retainer needed), and those who treat the retainer as fixed overhead like accounting or commercial insurance. The most expensive group is the in-between — clients who think they will run it themselves but don't have anyone whose actual job is to do so.
How we price it, and why fixed monthly
Pricing is fixed monthly, scoped to the system complexity tier (single site, multi-site, MIS, MIS + Flutter app + integrations). The fixed model exists because hourly billing for ops creates the wrong incentive — we would benefit from things being broken. Fixed monthly aligns us with the client: we benefit from things being boring, well-monitored, well-patched, and well-backed-up.
Tiers are published in the contract with the threshold metrics that move a client up a tier (number of transactions, number of integrations, number of distinct apps). When the threshold is crossed, the next tier kicks in on the following month — no surprise mid-month upgrades.
The handoff promise
Every retainer client is also a handoff client at any moment. The hosting account, the domain registrar, the source code, the CI/CD configuration, the secrets, the runbooks, and the documentation are all the client's property and reside in client-owned accounts. We hold operational credentials in our own vault, but the client has a master account they can take back inside one business day. The retainer renews monthly with 30 days' notice on either side. We have never sued a client for trying to leave; we've also never had a client leave for cause. That is the relationship we are trying to build.
Onboarding to the retainer
Two weeks of structured handover whether we built the system or took it over:
Week 1. Inventory: hosting, DNS, third parties, current monitoring, current backups, current security posture. Read-only audit. Documented architecture diagram. Risk register with severity-ranked items.
Week 2. Install our monitoring and log shipping. Configure backup verification jobs. Patch the highest-severity items from the risk register. Hand the client a one-page "what we found, what we fixed, what we'll keep watching."
From month three onward, the relationship is mostly invisible. That is the point. Boring is the deliverable.