Every client we work with arrives at a slightly different point on the same journey. Some have a clear feature list and a deadline. Others have a problem ("our staff spend two hours a day copying data between three systems") and no idea what the solution looks like. The process below is the one we have refined over years of shipping websites, information management systems, mobile apps and the hosting that keeps them running. It is deliberately the same shape regardless of project size — what changes is the depth of each stage, not the order.
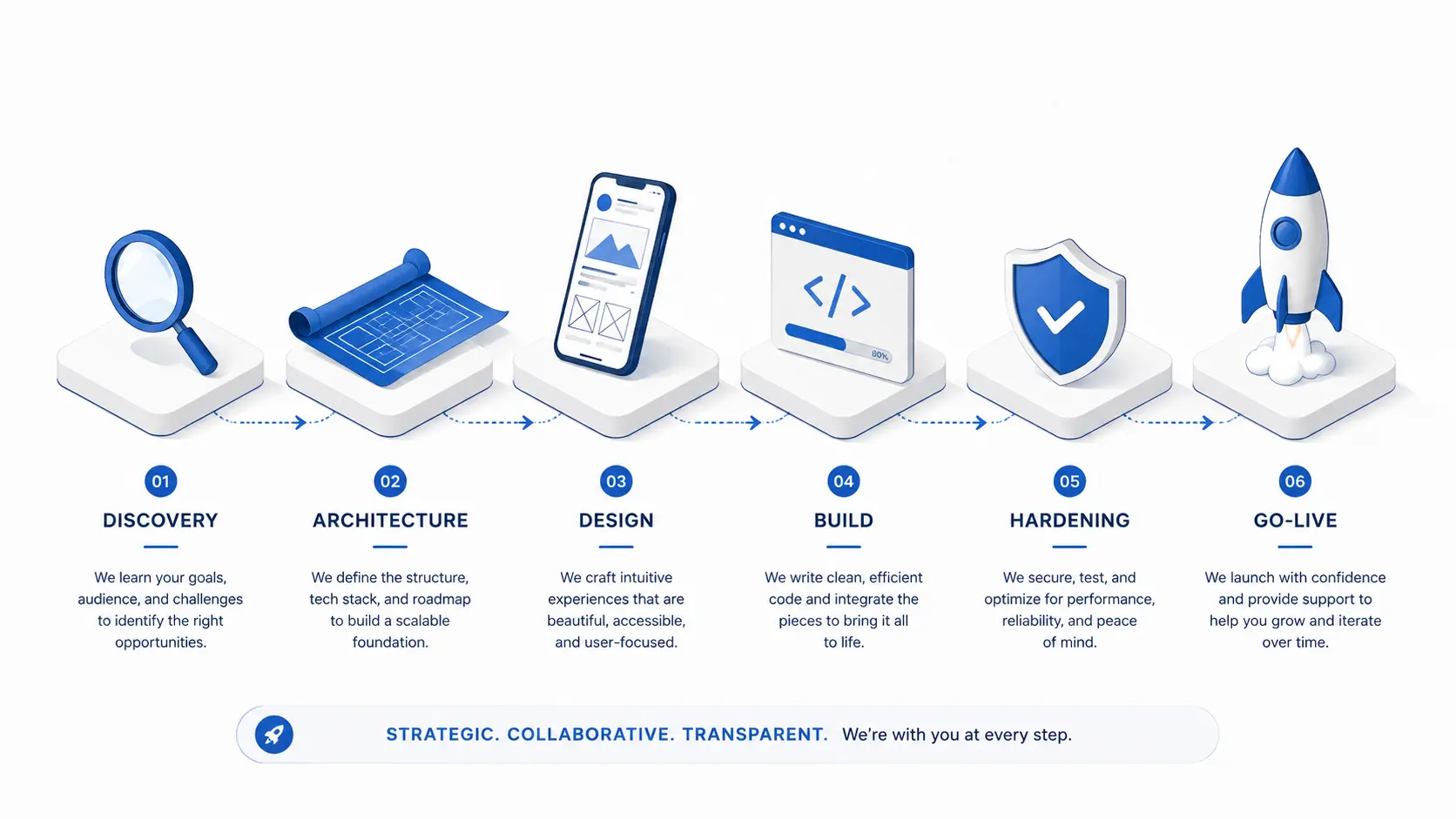
Stage 1 — Discovery and scope (week 1)
We start with a 90-minute discovery workshop, in person or remote. The goal of week one is not to start building — it is to make sure we are building the right thing. We map current state, list the painful workflows, define who actually uses the system (often very different from who paid for it), and decide what success looks like in three measurable numbers. By the end of the week the client owns a one-page scope document they can show anyone in their organization without explaining it.
Stage 2 — Architecture and proposal (week 2)
We translate the discovery findings into a concrete technical proposal. For a website, that is the tech stack (typically Laravel + MySQL + Nginx, with a Tailwind front end), the page tree, and the content model. For an information system, it is the entity model, the role-based permission matrix, and the integration points with whatever the client already runs — accounting software, ERP, e-commerce, signage. For a mobile app, it is the platform decision (we default to Flutter for cross-platform work), the API contract, and the offline-first behavior. The deliverable is a clear price, a clear timeline, and a clear list of "what we will not be doing."
Stage 3 — Design and prototype (weeks 3–4)
Design is not "make it pretty." Design is "make it usable by the actual person who will sit in front of it eight hours a day." We build clickable prototypes early — within the first ten days of design — and put them in front of two or three real users. We watch them try to complete tasks without us explaining anything. Every misclick is free information. The design that ships looks different from the first mockup almost every time.
Stage 4 — Build (weeks 4–10, scope-dependent)
Build is run in two-week sprints. At the end of every sprint, the client sees something working — not slides, not screenshots, working software in a staging environment they can log into. We commit to two non-negotiables during build: every feature ships with tests, and every database change ships with a reversible migration. These are not luxuries; they are the reason day 31 still goes well.
Stage 5 — Pre-launch hardening (week before go-live)
One week before go-live we shift gears from feature work to hardening. We run a security pass — Laravel-side input validation, CSRF, rate limiting, SQL parameterization audit, dependency vulnerability scan. We run a performance pass — query plans on the slow queries, Nginx caching, image optimization, asset bundling. We run an SEO and AEO pass — schema markup, sitemap, structured FAQ blocks for AI engines to cite. We run a backup-restore drill — because the right time to confirm backups work is before the first incident, not during it.
Stage 6 — Go-live and the first 30 days
Day zero is launch. Days 1–30 are stabilization. We monitor every error, every slow request, every failed login. Most projects produce a small list of "we did not see this in staging" issues in the first week; we fix them inside 24 hours. By day 30 the project is on the standard operational rhythm: weekly automated backups, monthly security patches, a quarterly architecture review.
Ongoing — Hosting and managed operations
For clients who want it, we keep running the infrastructure. That means a hardened Nginx + Laravel + MySQL stack with off-site daily backups, automated TLS renewal, intrusion-detection alerting, and a defined SLA on response times. Clients who run their own infrastructure get the same playbook and the documentation to follow it. Either way, the goal is the same: the system the client paid for in week one is still answering the phone five years later.
What we will not promise
We will not promise a fixed price on a project where the scope is genuinely unknown — discovery first, price second. We will not promise to ship in two weeks what takes ten. And we will not promise to build something we think the client should not build; if discovery reveals the right answer is "buy this SaaS instead and configure it well," we will say so. The relationship is worth more than the invoice.