If you needed a single story to explain why "AI infrastructure security" deserves its own budget line in 2026, this is it. On April 21, GitHub published advisory CVE-2026-33626, a Server-Side Request Forgery (SSRF) vulnerability in LMDeploy — a popular open-source toolkit for compressing, deploying, and serving large language models. Twelve hours and thirty-one minutes later, Sysdig caught the first in-the-wild exploitation attempt against its honeypot. Less than thirteen hours from public disclosure to active abuse.
Where the Bug Lives
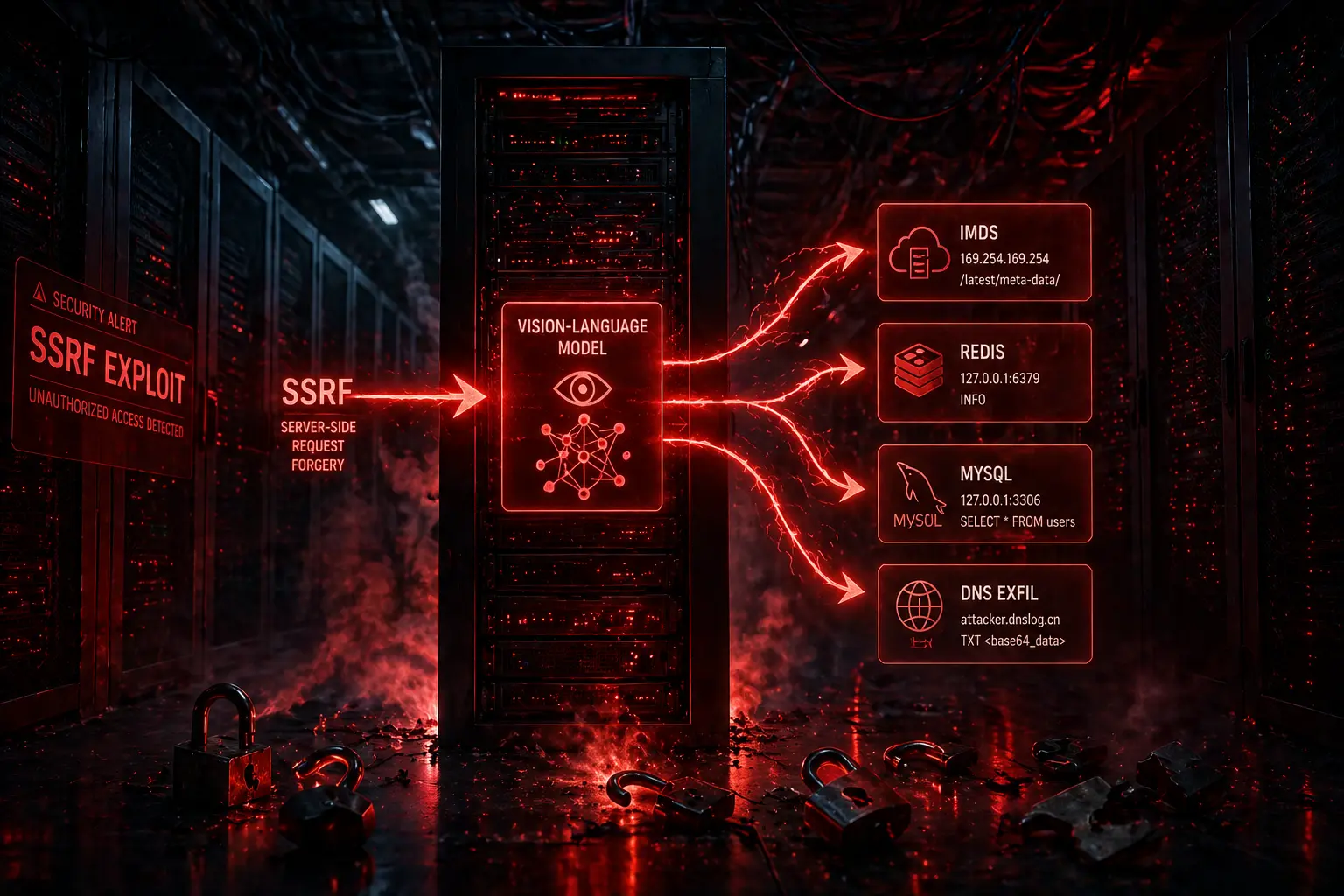
The flaw lives in lmdeploy/vl/utils.py, in a function called load_image(). When a vision-language model is asked to caption or analyze an image, the server fetches the image URL the user provides. The vulnerable version did not validate whether that URL pointed at a public asset or at an internal IP — meaning anyone who could send a model request could ask the server to fetch arbitrary internal endpoints on its behalf. The CVSS score is 7.5, which sounds moderate until you read what the attackers actually did with it.
What an Eight-Minute Attack Looks Like
In an eight-minute session, the attacker chained ten requests across three phases, switching between vision-language models like internlm-xcomposer2 and OpenGVLab/InternVL2-8B. They used the image loader as a generic HTTP SSRF primitive and port-scanned the internal network behind the model server. Targets included the AWS Instance Metadata Service (IMDS) — historically the goldmine for stealing cloud IAM credentials — Redis, MySQL, an internal HTTP admin interface, and an out-of-band DNS exfiltration endpoint. In other words: the model was politely asked to caption an image, and instead handed over a map of the entire backend.
The New Shape of AI Security
This is the new shape of AI security. The vulnerability is not in the model's weights, the prompt, or the alignment layer. It is in the boring HTTP plumbing around the model — the same kind of input validation oversight that has bitten web frameworks for two decades. The only difference is that the LLM serving stack is so new, and the rush to ship is so intense, that classical mistakes are being shipped at scale by teams who would never have made them in a Django or Spring app.
Three Things That Deserve Special Attention
First, the speed. Thirteen hours is faster than most enterprises can even acknowledge a CVE, let alone patch it. Sysdig's data implies that opportunistic scanners are now sitting on GitHub's advisory feed and weaponizing new disclosures within the same business day. If your AI inference servers are public-facing, "we'll patch in the next sprint" is no longer a defensible posture.
Second, the blast radius. SSRF against a model server is far more dangerous than SSRF against a normal web app, because the model server typically has elevated network access — it pulls model weights from S3, talks to vector databases, queries internal feature stores. Whatever the model can reach, the attacker can now reach.
Third, the patch. LMDeploy 0.12.3 fixes the issue with proper URL validation and IP allow-listing — exactly the kind of mitigation the OWASP SSRF cheat sheet has prescribed since 2017. If you run any AI inference service, your own image- or URL-fetching code paths deserve an audit this week, not next month.
My Take
This incident is a preview of the next two years. The AI infrastructure stack — Triton, vLLM, LMDeploy, Ollama, LiteLLM, every serving framework — is essentially Web 1.0 plumbing wrapped around 2026 models. We are about to discover, painfully, that "deploy an LLM in five minutes" was always a marketing slogan and never a security stance. The teams that win the next breach cycle won't have the most advanced AI; they'll have the most boring, disciplined, web-app-grade hygiene applied to their AI surface area. Validate every URL. Block IMDS by default. Treat the model server like any other internet-facing API — because to attackers, it already is.
Sources
- LMDeploy CVE-2026-33626 Flaw Exploited Within 13 Hours of Disclosure — The Hacker News
- CVE-2026-33626: How attackers exploited LMDeploy LLM Inference Engines in 12 hours — Sysdig
- CVE-2026-33626: Internlm Lmdeploy SSRF Vulnerability — SentinelOne