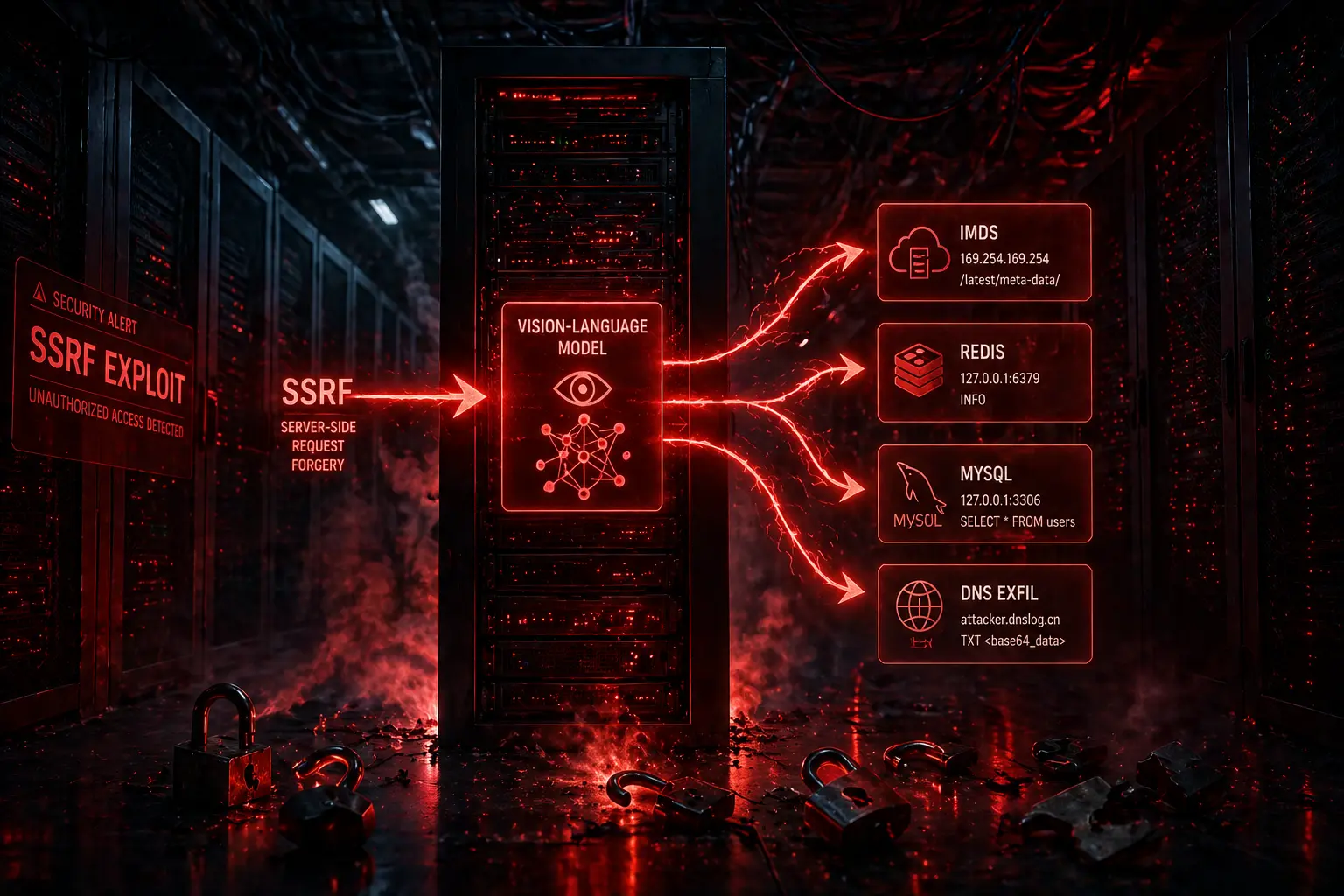
如果你只能用一個故事來解釋「AI 基礎設施資安」為什麼在 2026 年值得單獨開一條預算項,那就是這一篇。四月二十一日,GitHub 公開了編號 CVE-2026-33626 的安全公告,內容是知名開源工具 LMDeploy(一套用來壓縮、部署、伺服大型語言模型的工具包)出現了 Server-Side Request Forgery(伺服器端請求偽造,SSRF)漏洞。十二小時三十一分鐘之後,雲端資安公司 Sysdig 的蜜罐就攔截到第一波野外攻擊。從公開到被武器化,不到十三小時。
漏洞長在哪裡
漏洞位置在 lmdeploy/vl/utils.py 的 load_image() 函式。當視覺語言模型被要求對一張圖片做說明或分析時,伺服器會去抓使用者給的圖片網址。問題是有問題的版本沒有檢查那個網址是指向公開資源、還是指向內網 IP。意思是:任何可以送出模型請求的人,都可以叫伺服器代替自己去打內網任意端點。CVSS 是 7.5,聽起來中等,但你看完攻擊者實際做了什麼就笑不出來了。
八分鐘的攻擊長什麼樣子
在八分鐘內,攻擊者串了十個請求、走了三個階段,途中還在 internlm-xcomposer2 與 OpenGVLab/InternVL2-8B 等不同視覺語言模型之間切換。他們把圖片載入器當成一個通用 HTTP SSRF 工具,對模型伺服器後方的內網做埠口掃描。目標包括 AWS 的 Instance Metadata Service(IMDS,過去就是雲端身份權杖外洩的金礦)、Redis、MySQL、一個內部的 HTTP 管理介面,以及一個帶外(OOB)的 DNS 滲漏端點。換句話說:模型被「禮貌地」要求去看一張圖,回報的卻是整個後端網路地圖。
AI 資安的新形狀
這就是 AI 資安的新形狀。漏洞不在模型權重、不在提示詞、也不在對齊層,而在模型周邊那些不起眼的 HTTP 管線——也就是過去二十年讓無數網頁框架掉坑的「沒驗證輸入」這種老問題。差別只是 LLM 服務堆疊太新、上市壓力太大,於是那些在 Django 或 Spring 裡早就不會犯的錯,現在被一群急著出貨的團隊大規模重新犯了一次。
三件特別值得停下來看的事
第一,速度。十三小時比大多數企業「確認」一個 CVE 的時間還短,更別提修補了。Sysdig 的數據意味著現在已經有掃描者天天蹲在 GitHub 公告上,當天上班時間內就能把新公告武器化。如果你的 AI 推論伺服器有對外服務,「下個 Sprint 再修」這種回答已經沒有防守力。
第二,影響半徑。同樣的 SSRF 打在模型伺服器上,遠比打在一般 Web 應用上致命,因為模型伺服器通常擁有更高的網路權限——要從 S3 拉模型、要打向量資料庫、要查內部特徵庫。模型能到的地方,攻擊者就都能到。
第三,修補方式。LMDeploy 0.12.3 透過正確的 URL 驗證與 IP 白名單修掉這個問題,正是 OWASP SSRF cheat sheet 從 2017 年就一直在勸的標準作法。如果你正在運行任何 AI 推論服務,這禮拜就該對自家專案中所有「抓 URL / 抓圖片」的程式路徑做一次審計,不要拖到下個月。
我的觀點
這次事件是未來兩年的預告。整個 AI 基礎設施堆疊——Triton、vLLM、LMDeploy、Ollama、LiteLLM、所有伺服框架——本質上就是把 Web 1.0 的管線包在 2026 年的模型外面。我們即將很痛地發現:「五分鐘部署 LLM」一直都是一句行銷標語,從來不是資安姿態。下一波資安事件後,能站著走出來的團隊,不會是擁有最先進 AI 的那家,而是把無聊但紮實的「網頁應用級資安衛生」全部套用到 AI 介面上的那家。每個 URL 都驗證、預設封鎖 IMDS、把模型伺服器當成「會被當網際網路 API 攻」來看待——因為對攻擊者來說,它本來就已經是了。
資料來源
- LMDeploy CVE-2026-33626 Flaw Exploited Within 13 Hours of Disclosure — The Hacker News
- CVE-2026-33626: How attackers exploited LMDeploy LLM Inference Engines in 12 hours — Sysdig
- CVE-2026-33626: Internlm Lmdeploy SSRF Vulnerability — SentinelOne